《Nature Machine Intelligence》:AI+新材料,大语言模型-材料科学研究方向预测
编辑:zcniszc 时间:2026年04月13日 访问次数:1476
鉴于科研论文发表数量呈指数级增长,即便是同一研究领域的科学家,也已无法通读所有文献。
近日,德国卡尔斯鲁厄理工学院Thomas Marwitz, Pascal Friederich等在Nature Machine Intelligence上发文,研究探索利用大语言模型,从材料科学领域的论文摘要中,提取核心概念与语义信息,以识别人类尚未察觉的关联,并提出了具有启发性的近期及中期未来研究方向。
研究证明,相比于自动化关键词提取方法,大语言模型能更高效地提取概念,并构建起作为科学文献抽象表征的概念图谱。基于历史数据,还训练了机器学习模型,用于预测概念的新兴组合,即新的研究思路。
研究表明,融合语义概念信息,可提升预测性能。通过与领域专家进行个性化模型建议的定性访谈,验证了该模型的实用性。结果表明,该模型通过预测尚未被探索的创新概念组合,激发材料科学家的创造思维。
Predicting new research directions in materials science using large language models and concept graphs.
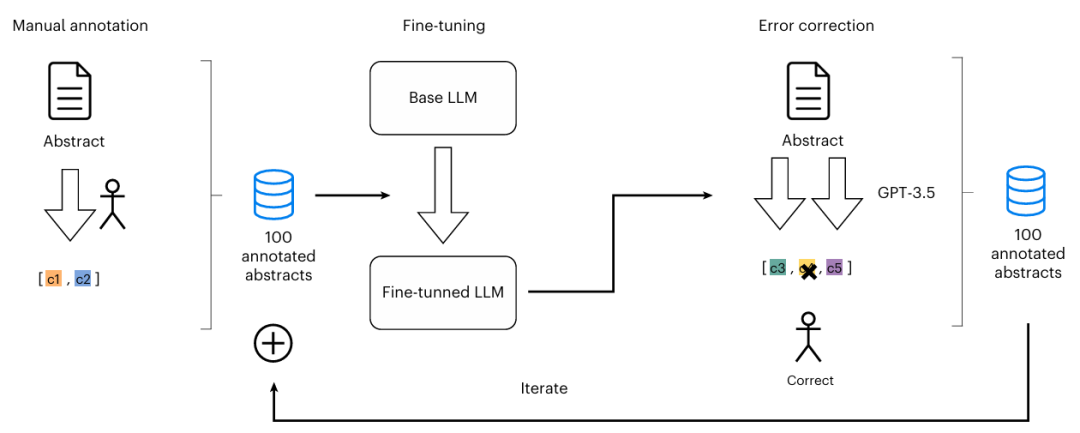
图1: 标注数据的生成。
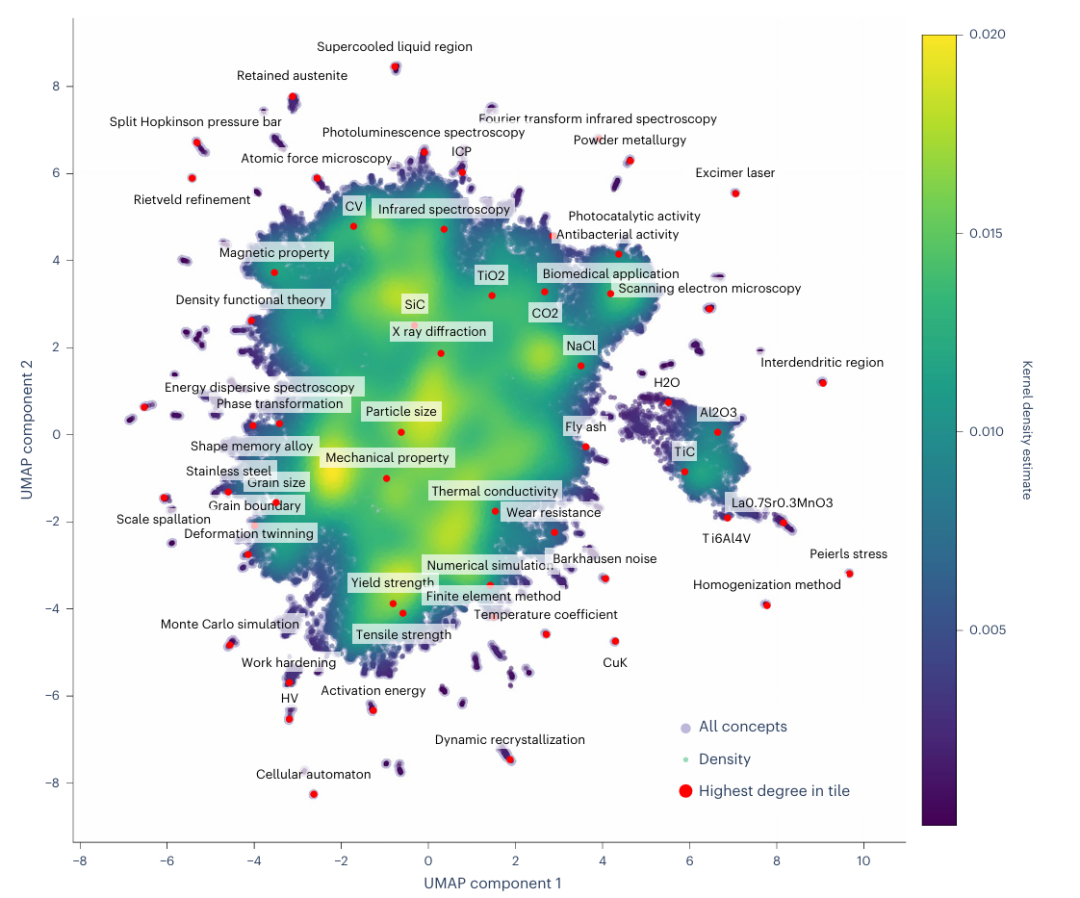
图2: 材料科学图谱。
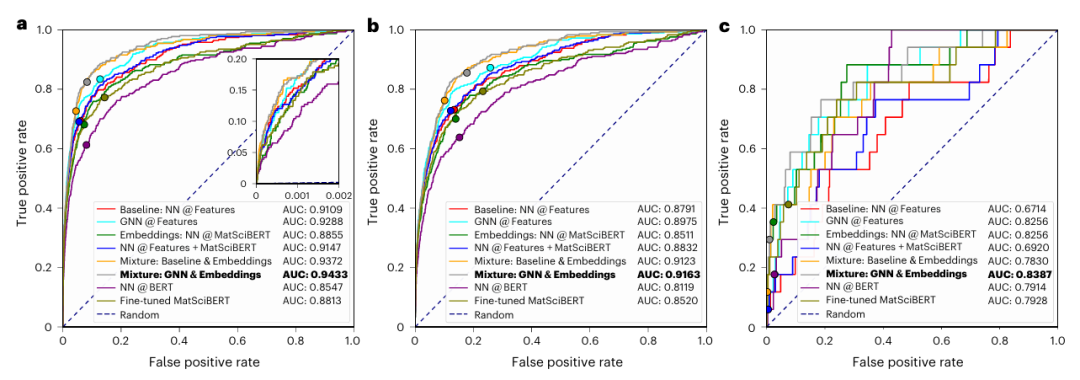
图3: 在测试集上,预测模型的性能指标。
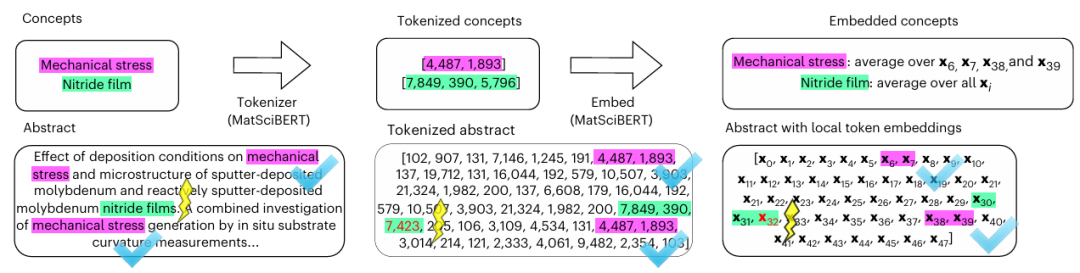
图4: 从摘要中,计算概念嵌入的示例。
首先从OpenAlex数据库中,筛选了1955年至2022年间发表的约22万篇材料科学相关论文。以100篇人工标注的摘要为基础,微调Llama-2-13B大语言模型并迭代优化,最终从海量文本中,提取出约137万个核心概念(如“机械应力”、“氧化石墨烯”),构建了包含1300万条边的动态演化概念图。机器学习:混合模型通过加权融合图神经网络(GraphSAGE,用于捕捉节点局部结构)和语义嵌入(MatSciBERT,用于理解概念内涵)的预测结果,在预测2020-2022年间新形成的概念链接时,取得了最优性能(AUC 0.9433)。Marwitz, T., Colsmann, A., Breitung, B. et al. Predicting new research directions in materials science using large language models and concept graphs. Nat Mach Intell (2026). https://doi.org/10.1038/s42256-026-01206-y